
The purpose of Massively Parallel Processing (MPP) is to scale out compute nodes and reduce workload per compute node to query large volumes of data.
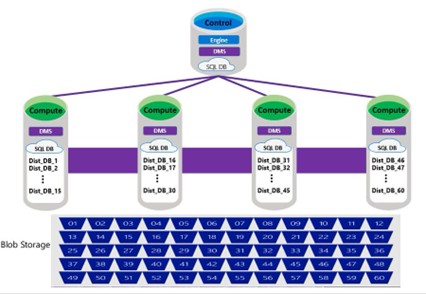
Control Node
There will always be 1 Control Node that is used to connect to and manage the SQL Pool. However, the data in a table is always sharded into 60 data distributions that are stored on premium blob storage. The picture above is an example of DWU 2000.
Compute Nodes and Scaling
You can scale from 1-60 Compute Nodes by choosing a Data Warehouse Unit (DWU). So, as the DWU increases the number of Distributions per node decreases. (60/Compute Nodes = Distribution per node). DWU 2000 is 60/4 = 15 distributions per node. Data Warehouse Units are also how you scale the amount of Memory per data warehouse, size of the TempDB, and the amount of Adaptive Cache.

Data Distribution
But how the data is sharded across the distributions is determined by one of three table geometries. Hash-Distributed, Round Robin (Default), and Replicated Table. Distributed tables design guidance – Azure Synapse Analytics
Hash-Distributed will divide the data by using a hashing function on a single column. This is to make sure that the same value always goes to the same distribution. Data Types matter as an Integer is not the same as a Big Integer.
Round Robin table will evenly divide the data across data distributions and is great for staging or loading tables but will slow down queries based on data movement.
Replicated Tables start off as Round Robin but will create a copy of a table that is cached at each compute node when it is first read. Great for small (>2GB), static, dimension tables.
The best way to see the MPP architecture in action is to use the DBCC PDW_SHOWSPACEUSED (‘tablename’) command. The “rows” column will show if the data is distributed evenly (RR) or not (HD). The pdw_node_id shows how many compute nodes are being used. The distribution_id will show how many distributions are mapped to each compute node.




Be the first to comment on "MPP Architecture in Synapse SQL Pools"