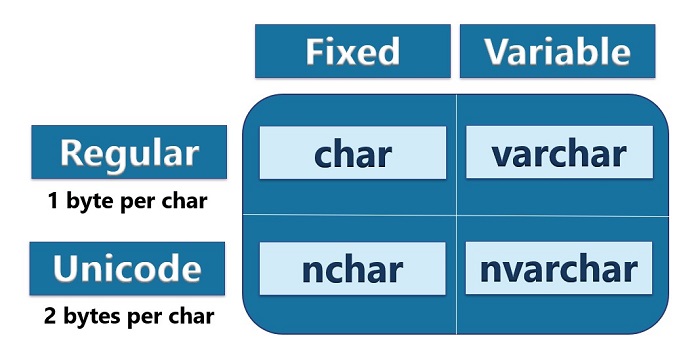
Regular Character Data Types
Both the char and varchar data types are considered regular or non-Unicode character data types. Each alphanumeric character uses only one byte of data.
This contrasts with the Unicode character data types (nchar and nvarchar). These use two bytes of data for each alphanumeric character. We will talk more about Unicode data types later in this post. But for now, we will focus on char and varchar.
What is the difference between char and varchar?
The difference between the two regular data types is that the char data type is fixed length while the varchar data type is variable length. Notice the variable length data type starts with var.
In our example below, the char(10) data type will hold up to ten characters. This will require us to fill all ten characters. If all ten characters are not used, then spaces will be added to fill in the extra characters. In the case of the varchar(10) data type, we only use the space needed and will not use what we don’t need.
A fancy restaurant analogy
An analogy would be if we made a reservation at a fancy restaurant for a table with ten chairs. What if only five people showed up? Then the restaurant would have the option to either charge us for all ten seats, including those we did not use. Or take away five chairs and only charge us for the five seats we did use.
In the case where we were charged for the extra five chairs, this would be similar to the fixed length char(10) data type. In the case where we were not charged for the five extra chairs, this would be like the variable length varchar(10) data type. However, instead of chairs, we are concerned about bytes.
Demonstrating Regular Character Data Types
To demonstrate our regular character data types, we will start with some sample code.
DECLARE @String1 as char(10) = 'Hello'
DECLARE @String2 as varchar(10) = 'World'
SELECT @String1 + @String2
SELECT LEN(@String1), LEN(@String2)
SELECT DATALENGTH(@String1), DATALENGTH(@String2)Lines 1 and 2, we are declaring two variables. The first variable named @String1 will be a char(10) data type. The second variable will be named @String2 with a data type of varchar(10).
SQL Server 2008 and later you can initialize or set a value to a variable on the same line that you declare the variable. In this case, we will assign the text value ‘Hello’ to the @String1 variable and then the text value of ‘World’ to the @String2 variable.
With the sample code, we are using concatenation to paste the two string variables together. As you will see below, since @String1 is char(10) data type, five spaces were added after the word ‘Hello’. However, in the case of @String2, which is a varchar(10), the extra five spaces were not added after the word ‘World’.
SELECT @String1 + @String2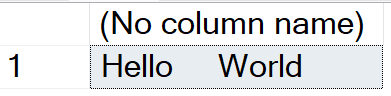
Since this may be difficult to see, we will use two String functions to demonstrate this result. We use the LEN function to see how many characters are in each variable. As you see for both @String1 and @String2 it shows that each have five characters. (‘Hello’ for @String1 and ‘World’ for @String2)
SELECT LEN(@String1), LEN(@String2)
Next, we use the DATALENGTH function which instead of showing how many characters that are being used in each variable, the result set shows how many bytes are being used in each variable. As you see @String1 is using ten bytes while @String2 is only using five bytes.
SELECT DATALENGTH(@String1), DATALENGTH(@String2)
Unicode Character Data Types
Let’s discuss the nchar (fixed length) and nvarchar (variable length) Unicode character data types. These are both similar to the Regular character data types except as previously mentioned they use two bytes per alphanumeric character.
What is Unicode?
You can think of Unicode as Universal code and the ‘n‘ in front of the data type names as Nationalized. These data types are used for languages that have larger character sets and need more space. For example, the English language only uses about 85 values in its characters set. (Uppercase A-Z, lowercase a-z, 0-9, and about twenty special characters.) So, for the English language only one byte is needed to represent its character set. Therefore, Regular or non-Unicode character data types are used.
Used for Non-Latin Based Languages
However, many non-English languages have thousands of characters in their language, so two bytes are needed to represent their character sets. This will allow for 65,536 values to be stored. That is why the Unicode data types are needed. Some languages need even more room for their character sets, but that is beyond the scope of this post.
Demonstrating Unicode Character Data Types
Now let’s use the same examples as above except we will add the ‘n’ in front of the data types. We will also add a capital N in front of the text strings ‘Hello’ and ‘World‘. This will explicitly convert the text data to Unicode data type. If the capital N is not included on our text strings, they will implicitly convert to the correct data type if only English characters were used. Using the capital N is to ensure that if a non-English character were added in the text string it would be converted correctly.
DECLARE @String1 as nchar(10) = N'Hello'
DECLARE @String2 as nvarchar(10) = N'World'Now that we have changed the data types of our variables to Unicode, let us run our three SELECT statements to see what has changed. First the statement that concatenates the two variables. You should notice that there is no visible difference from Regular character data types and the Unicode character data types.
SELECT @String1 + @String2
And if we look at the LEN function to see how many characters are being stored in the Unicode data types, again nothing changes in the results. Both variables still hold five characters each.
SELECT LEN(@String1), LEN(@String2)
Now when we run the DATALENGTH function we will see the difference in the number of bytes used. You will notice that the Unicode data types use twice as many bytes as the Regular data types.
SELECT DATALENGTH(@String1), DATALENGTH(@String2)
MAX Character Data Types
Hopefully, this will help you when working with different character data types. One final note, character data types are limited in the number of characters that they can use, specifically they are limited to the size of a data page. So, the limit for the Regular data type is varchar(8000) and for the Unicode data type the limit is nvarchar(4000).
Prior to SQL Server 2008 you could use either the text or ntext data types if you need more characters than the limit. However, the text and ntext data types have been deprecated. Use either varchar(MAX) or nvarchar(MAX) should be used in those situations. For best performance though, you should right-size your data types to only use what you need. Additionally, as a precaution, always validate your data to protect yourself from SQL Injection attacks. Especially when using the MAX data types.



Great post with some good analogies and examples.