
Understanding SQL Server Query Plans:
Clients often ask what I look for when tuning queries for performance. So, I decided to put together this list where opportunities for optimization can be found. Now, these are just initial steps to get started looking for pain points in our execution plans. It is important to understand that every query and plan is unique. Therefore, what proves effective for one plan may not necessarily be optimal for a similar plan.
Warnings:
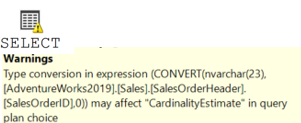
This is the query optimizers way of telling you where it hurts. Warnings provide information about potential issues with the plan that could degrade query performance. This could include missing indexes, implicit data type conversions, or bad cardinality estimates. It’s essential to address these warnings to avoid performance bottlenecks.
Left Most Operator:
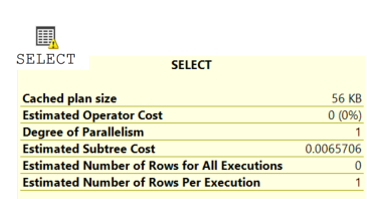
When we are tuning a query, it is important that we “First, do no harm.” We do this by establishing a baseline for analysis. This determines whether our optimizations are enhancing the query or not. This is why we start by selecting the left most operator to document the plan properties. Including operator cost, memory grants, and plan size.
Right to Left Analysis:

The execution plan displays the order in which a query is run. The query begins from the right side of the plan and goes to the left. This is the same order that we would troubleshoot the plan. Addressing issues early in the execution plan allows us to resolve problems that might cascade down the plan that impacts later steps. The earlier we solve the problem the faster our job is done.
Expensive Operators:
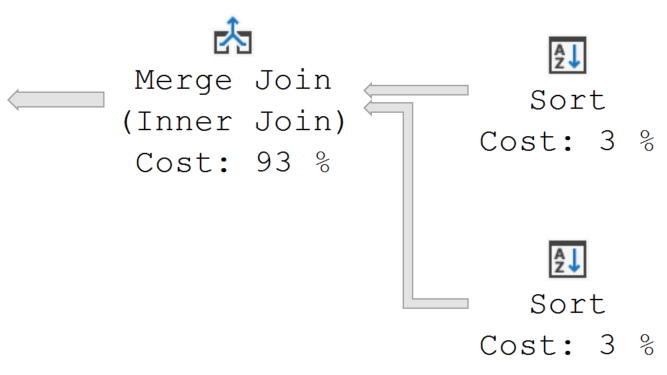
There are some that disagree with this suggestion as the cost percentage of an operator does not provide any useful information. In the picture above the Merge Join operator shows that it used 93% of the time to run the query. That really is not completely accurate. It’s just where the traffic jam occurred, but not what slowed down our query. I personally like to use this to locate pain points and then look at the preceding steps to find where the actual problem lies. In this case the two Sort operators that only have a cost of 3% each are the actual issues in this plan.
Sort Operators:

Sort operators are not fundamentally problematic and may be the most efficient method for executing a specific query. However, when you see Sort operators, you do want to ask why they are there and are they necessary. Examine the search arguments in the WHERE clause or the columns in the JOIN clauses to determine if they are introducing unnecessary Sort operations.
Data Flow Statistics:

The thickness of the arrows in a plan indicates the number of records being passed from one operator to the next. Typically, it is expected to see arrows getting thinner and not thicker as the query progresses. Notice in the picture above that the two arrows to the right of the Merge Join are thinner with values of 113443 and 89253 respectively. However, the arrow becomes thicker when exiting the operator with a value of almost 2 billion. This definitely indicates an issue that needs investigating. In this case the query was joining tables in a many-to-many relationship.
Nested Loop Operator:
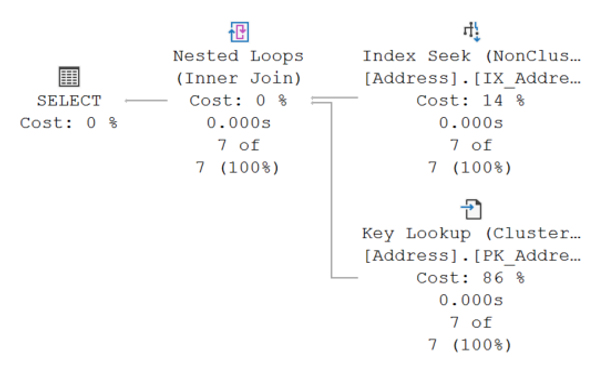
Nested loop operators are not inherently inefficient and can sometimes be the best method for joining result sets. However, they may cause performance issues with larger data sets due to increased I/O and CPU costs. To address these issues, it might be useful to use a covering index. A covering index is a non-clustered index that includes all the columns required by a query, which eliminates the need for additional lookups. It is important to note that we do want to create too many indexes for a table which could lead to other performance issues when updating records or performing maintenance jobs.
Scans vs. Seeks:
A table or clustered index scan occurs when SQL Server scans the data or index pages to locate relevant records. In contrast, index seeks are more efficient because they directly navigate to the rows that are needed for the results. Seeks typically involve fewer I/O operations compared to scans. While scans may still be the most effective method for retrieving large datasets, writing queries with more selective search arguments can lead to better utilization of your indexes.
Skewed Estimates:

In the Index Seek operator above we can see 4688 rows of an estimated 130 rows were returned creating a skewed estimate of 3606%. In this case, it was caused by the reuse of a parameter sensitive plan. However, another cause of skewed estimates could be outdated or inaccurate statistics that can significantly affect the effectiveness of our query plan. This results in suboptimal index utilization, incorrect join selection, and improper allocation of CPU and memory resources. By regularly updating statistics, the optimizer is provided with more precise data distribution in a table or index, which leads to more effective query plans and enhanced performance.
Conclusion:
As mentioned at the beginning of this post, these are just initial steps in finding opportunities for the optimization of your queries. There are cases where you might need deeper analysis. However, it is a best practice to consistently review query plans for any database administrator or developer who aspires to maintain efficient and responsive databases.



Be the first to comment on "Opportunities for Query Optimization"