Transaction Isolation Levels are used to provide concurrency control within SQL. In a previous post, we discussed how Locks are used in isolating transactions to provide data consistency and to control concurrency.
What is Concurrency?
Concurrency is the ability of multiple users to access data simultaneously without their data modifications conflicting with each other. If you have a high level of concurrency, that means many users can access the same data during a given time period. The lowest level of concurrency is when only one person can access the data at a given point in time. The correct level really depends on access needs and how the data is being used.
Concurrency Control
SQL Server provides two types of Concurrency Control, either Pessimistic or Optimistic.
Pessimistic Concurrency Control
This concurrency type will use locks to control access to the data based on Lock Modes and Locking Granularity. Specifically, when a user accesses data that causes a lock to happen on a record or a range of records, other users are prevented from accessing that data until the first user releases the lock. This type of concurrency control is used when there is high contention for data access.
Optimistic Concurrency Control
This concurrency type is used in an environment where there is lower contention for data access. Users will not use locks when they read data. Instead, when a user tries to update records, they will check to see if the data has been changed since the first time, they read the data.
In SQL Server, this is managed by using the TempDB database that provides row versioning of each record being modified. To implement optimistic concurrency control, you would need to implement one of the two snapshot isolation levels.
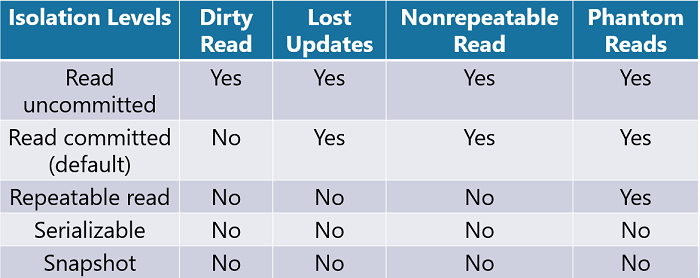
Pessimistic Isolation Levels
The SQL Server Database Engine uses locking to support four levels of pessimistic transaction isolation. Read Uncommitted, Read Committed, Repeatable Read, and Serializable.
Read Uncommitted
This provides the highest concurrency level with the lowest level of locking. Transactions are only isolated enough to prevent users from reading corrupted data. Dirty reads will occur with this isolation level.
Read Committed
This is the default setting in SQL Server. The database engine will keep write locks on records until the end of a transaction but will release read locks once a SELECT statement has been executed. This will prevent dirty reads but still allows for other concurrency problems.
Repeatable Read
With this isolation level, the database engine will keep both read and write locks on records until the end of a transaction. Like the Read Committed isolation level, this will prevent dirty reads.
But it will also prevent the concurrency issues of lost updates and non-repeatable reads. However, this level does not manage range-locks, so phantom reads could still occur.
Serializable
The highest level of transaction isolation that will keep both read and write locks on records until the end of a transaction. But unlike the repeatable read isolation level, range-locks will be acquired.
This occurs when a SELECT statement that has a WHERE clause retrieves a range of records. This is helpful to prevent the concurrency problem of phantom reads.
Optimistic Isolation Levels
The SQL Server Database Engine uses row versioning to support the two levels of optimistic transaction isolation.
Read Committed Snapshot (RCSI)
This isolation level is implemented by setting the READ_COMMITTED_SNAPSHOT database option to ON. Row versioning is used instead of locks to provide a consistent snapshot of each record as it existed at the time the record was read.
Locks are not used to restrict updates from other transactions. When the snapshot database is set to OFF, the isolation level will revert to the Read Committed isolation level.
Snapshot
By turning the ALLOW_SNAPSHOT_ISOLATION database option to ON, row versioning would be used to provide read consistency of data. When a transaction reads records that may have been modified by another transaction, they would read the records as they existed at the beginning of the transaction. This is different from RCSI that provides a row version of a record from the time it was read.
Concurrency Problems
Dirty Reads
To understand dirty reads, sometimes known as an uncommitted dependency, it is important to understand how data is modified. When a DML statement is used to modify data, a data page is located or read into memory.
While the data page is being modified, but before it is written back to disk, it is considered to be a dirty data page. This is not a bad thing; it just means the data page is in the process of being updated. In most cases, we don’t want users to be able to read data if it has not been committed back to the database. (Dirty Read Example)
By default, SQL Server sets the isolation level for transactions to READ COMMITTED to prevent dirty reads. However, if we are more concerned with data concurrency and less concerned with users reading accurate data, we can change the Transaction Isolation Level to READ UNCOMMITTED.
Lost Updates
This is an issue when two or more transactions select the same row at the same time. Both transactions will update the row based on the original value that was read. The last transaction to update the row will overwrite the update from the other transactions causing a lost update.
To prevent this from happening we can change the isolation level to escalate the lock on the record. Keep in mind that this will reduce the concurrency on the record. (Lost Updates Example)
Nonrepeatable Read
This is sometimes known as “Inconsistent Analysis”. This issue occurs when a transaction accesses the same row several times and reads different data values each time.
This is caused by other transactions modifying the record in between data reads. Once again, this can be prevented by changing the isolation level of the transaction. (Nonrepeatable Read Example)
Phantom Reads
This issue happens when a range of records are selected by a user and in between the first time, they retrieve the records and subsequent reads of those records, a separate transaction inserts or deletes records in the range. (Phantom Read Example)



Be the first to comment on "Transaction Isolation Levels"