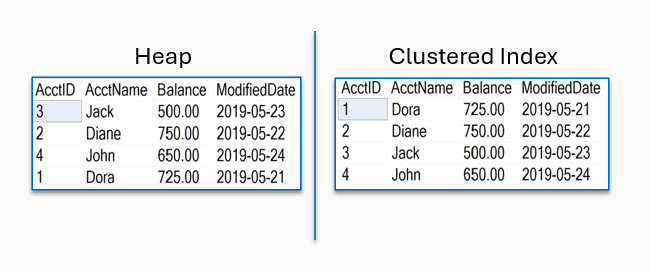
As mentioned in a previous post, table structures in SQL Server stores records in data pages. These records are either in an unsorted order (Heap) or a sorted order (Clustered Index).
If the data has not been provided a clustering key, the data would be unsorted. An unsorted data structure would be considered a Heap. When a clustering key is provided, the data rows will be sorted by that key. This is considered a Clustered Index. Let’s take a closer look at this in SQL Server.
What is a Heap?
First, we will create a table named Accounting.BankAccounts and INSERT four records. Notice that we have not created a Primary Key or any type of index for this table. Additionally, the values for the AcctID field have been inserted in random order.
Make sure that the AcctID is set to NOT NULL to make it easier to add a Primary Key later in this demo.
CREATE SCHEMA Accounting Authorization dbo
CREATE TABLE BankAccounts
(AcctID int NOT NULL,
AcctName char(15),
Balance money,
ModifiedDate date)
GO
INSERT INTO Accounting.BankAccounts
VALUES(3,'Jack',500, GETDATE()),
(2, 'Diane', 750, GETDATE()),
(4, 'John', 650, GETDATE()),
(1, 'Dora', 725, GETDATE())
GORun the SELECT statement. You will see that the records are returned in an unsorted order. This is because the data is stored in a heap. The data is returned in the order they were inserted.
SELECT AcctID, AcctName, Balance, ModifiedDate
FROM Accounting.BankAccounts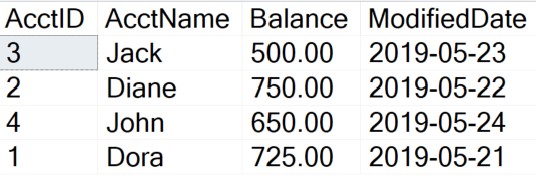
There are two other ways we can see that this data is in a heap. We can use two undocumented DBCC commands to look inside the actual data pages and or Execution Plan Table Operators.
Using the DBCC TRACEON and DBCC IND commands
We need to start with the DBCC TRACEON (3604) statement. This returns results to the messages pane. Then we run the DBCC IND statement to locate the data pages for the Accounting.BankAccounts table.
The first parameter for the DBCC IND statement is the database name. We put a 0 to indicate the current database. Next is the table name, Accounting.BankAccounts. The last parameter is how to view the data. We are using a -1 to show all of the indexes for this table.
DBCC TRACEON (3604)
DBCC IND (0,'Accounting.BankAccounts',-1)The first row of the DBCC IND displays the following information:

- PageFID: Indicates this is the first page in the database.
- PagePID: Indicates the Page ID of the page.
- IAMFID: Displays the location of the IAM page for this file
- IAMPID: Displays the location of the IAM page for this page
- ObjectID: This is the Object ID value of the dbo.Accounting table.
- IndexID: A value of 0 indicates the table is in a heap. A value of 1 indicates the table is in a clustered index. Any value greater than 1 indicates pages for a non-clustered index.
Two takeaways from this result is that the IndexID is 0 indicating the data is stored in a heap. Secondly, the data page has an ID of 320 that we will use for the DBCC Page command. This is a very small table of only four rows, so only one 8kb data page was needed.
Using the DBCC PAGE command
Now let’s use the DBCC PAGE command to look inside data page 320. Again, the first parameter is the current database. The second parameter is the File ID. The third argument is the page number. The final argument is to display everything inside the data page.
DBCC TRACEON (3604)
DBCC PAGE (0, 1, 320, 3)
In a blog post, it is not easy to slide up and down in a results pane. I just pulled out the relevant data for this demonstration. Slot 0 inside a data page indicates the first row. Column 1 for each result is for the AcctID field.
Slot 0 has an AcctID value of 3. The AcctID for Slot 1 is 2. And the third record (Slot 2) has a value of 4 for the first column. The key point is that the data is not in sorted order, therefore the data is in a heap.
Primary Keys vs Clustering Keys
A key point before we discuss Clustered Indexes. Primary Keys and Clustering Keys are not the same thing, even if they are typically the same value. Primary Keys are used to uniquely identify records. Clustering Keys are used to determine how to sort data in a data page.
Just because a table has a Primary Key does not always mean the table is in a Clustered Index. But it is the default when you create the Primary Key on a table.
What is a Clustered Index?
We will add a Primary Key that will create a Clustering Key. This will store the data in the order of the clustering key. Having a clustering key creates the Clustered Index.
ALTER TABLE Accounting.BankAccounts
ADD CONSTRAINT pk_acctID PRIMARY KEY (AcctID)When we run the SELECT statement again, we will notice that the records are returned in order by the AcctID field. This is because the table was rebuilt with a Clustered Index.
SELECT AcctID, AcctName, Balance, ModifiedDate
FROM Accounting.BankAccounts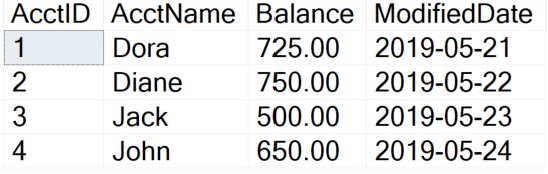
Now that we have added the Primary Key, we will re-run the DBCC IND commands again. Notice that the IndexID is now a 1. This indicate that the data is stored in a Clustered Index.
Additionally, the page numbers and ObjectID changed. This is because the table was rebuilt to create the clustered index and put the data in sorted order.
DBCC TRACEON (3604)
DBCC IND(0,'Accounting.BankAccounts',-1)
Run the DBCC PAGE Command on page 488. Notice the rows are in order by the AcctID field.
DBCC TRACEON (3604)
DBCC PAGE (0, 1, 488, 3)



Be the first to comment on "Table Structures in SQL Server"